术语
处理器: 物理芯片,以核或者硬件线程的方式包含了多个CPU
核: 一个多核处理器上的独立CPU实例
硬件线程: 一个钟支持在一个核上同时执行多个线程的CPU架构,每个线程是一个独立的CPU实例
CPU指令: CPU操作来源于它的指令集,指令用于算数操作、内存/IO和逻辑控制
逻辑CPU:又称虚拟CPU,处理可以通过硬件线程实现
调度器: 把CPU分配给线程运行的内核子系统
运行队列: 等待CPU服务的可运行线程队列
CPU内存缓存
为了提供内存I/O性能,处理器提供了多种硬件缓存,如
CPU寄存器->一级缓存->二级缓存->三级缓存->主存->存储设备->云存储
- 越左侧的缓存大小越小,速度越快,越靠近CPU
多处理器系统,内核通常为每个CPU都提供一个运行队列,并尽量使现场每次都被放到同一个队列中,这以为这现场更优可能运行在同一个CPU上, 因为CPU缓存了保存了它们的数据,这些数据被称为热度缓存,这种保持线程运行在相同CPU上的方法被称为CPU亲和性,提高了内存本地性
性能问题故障分析
通用准入性能分析60秒
黄金60秒尝试定位性能异常组件
uptime: 识别1分钟、5分钟、15分钟平均值负载
top : 检查概览
vmstat -SM 1 : 查看运行队列长度、交换和CPU整体使用情况
mpstat -P ALL 1: 查看CPU核心平衡情况,检查单个热点CPU,发现可能的线程扩展性问题
dmesg -T | tail: 查看内核日志,可能包含一些OOM错误
pidstat 1 : 查看每个进程的CPU使用情况
free -m: 查看内存使用情况,包括文件系统缓存
iostat -x 1: 磁盘IO统计,IOPS、吞吐量、平均等待时间和忙碌百分比
sar -n DEV 1 : 网络设置IO、数据包和吞吐量
sar -n TCP,ETCP 1 : TCP统计,连接率和重传
初步定位CPU开销
定位顺序如下
- 了解整个系统当前使用率是多少,每个CPU是多少
- 了解当前队列情况
- 用户与内核时间比
- 哪个应用或者用户使用CPU最多,用了多少
- 遇到了什么类型的停滞周期(比如IO还是内存)
- 为什么CPU被使用(用户和内核级别的调用路径,perf可以分析)
- 错误
- 系统调用频率
- 资源上下文切换频率
- 中断频率
cat /proc/softirqs - 中断的CPU用量是多少
零侵入CPU剖析
Perf 分析一个正在运行的程序
1.获得在运行的进程PID
2.开始采样perf record -F 49 -g -p <PID>
- 根据采样数据分析性能热点
perf report
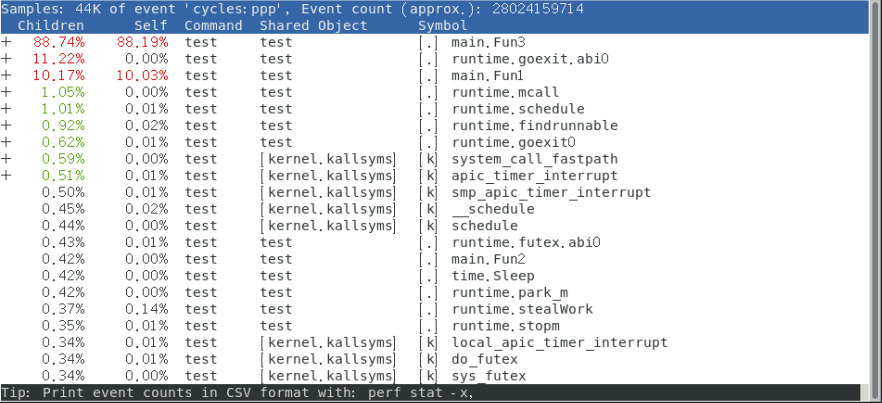
图中可以看出88%的性能开销来自main.Fun3函数,10%的性能损耗来自Main.fun1函数
输出结果:
- Overhead:指出了该Symbol采样在总采样中所占的百分比。在当前场景下,表示了该Symbol消耗的CPU时间占总CPU时间的百分比
- Command:进程名
- Shared Object:模块名, 比如具体哪个共享库,哪个可执行程序。
- Symbol:二进制模块中的符号名,如果是高级语言,比如C语言编写的程序,等价于函数名。
火焰图
git clone https://github.com/brendangregg/FlameGraph.git && cd FlameGraph
1.用perf script工具对perf.data进行解析
`perf script -i perf.data &> perf.unfold`
2.将perf.unfold中的符号进行折叠
`./stackcollapse-perf.pl perf.unfold &> perf.folded`
3.最后生成svg图:
`./flamegraph.pl perf.folded > perf.svg`